2.76 FAQ-820 Origin 中如何处理大型数据集?
Last Update: 11/27/2024
数据量的限制
Origin 中的数据可以包含在工作簿和矩阵中。每个工作簿最多可以包含1024个工作表。在一个工作表中,列数最多可达 65500,行数最多可达 9000万 (64 位系统)。实际上,受限于系统资源的限制(比如内存大小、CPU处理能力等),实际中可能达不到软件设计的上限。
矩阵窗口最多可以包含1024个矩阵表。每个矩阵表最多可以包含9000万个列 (1 行) 或9000万行 (1 列)。同样,受限于系统资源的限制(比如内存大小、CPU处理能力等),实际中可能达不到软件设计的上限。
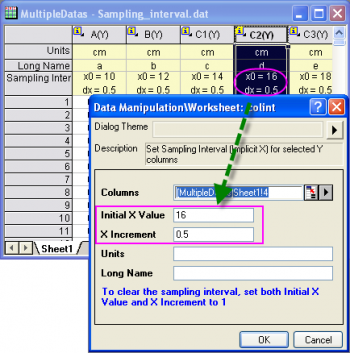
设置采样间隔
Origin 工作表列中支持采样间隔属性。如果与 Y 数据集关联的 X 值是均匀间隔的,则该信息可以存储为 Y 列的采样间隔。这将使得 Origin 工程文件的减小 50%,因为在工作表中不再需要 X 列作为显式列。这也提高了大型数据集的绘图和分析速度,因为不必从工作表列中对 X 信息进行读点。
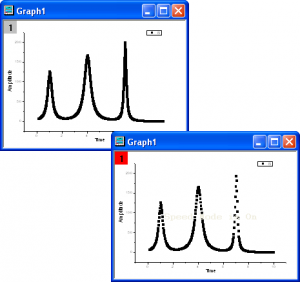
使用大型数据集进行绘图
默认情况下,在绘制大型数据集时会隐藏部分数据点。这称为 Speed Mode。在 Speed Mode 下绘制矩阵数据时,会在 X 和 Y 的数据维度中选择一个固定增量用于跳过部分点。对于工作表数据,Speed Mode 机制会更复杂一些,将会检查数据的性质,并选择表示整个数据形状的点的子集来绘图。在 Speed Mode 对话框中 (从菜单 Graph: Speed Mode 打开),可以选择低、中、高或自定义对 Speed Mode 的选项进行设置。然后可以将该设置保存为图形模板 (graph template) 的一部分,或存为主题 (theme) 并可以应用到其它图形中。
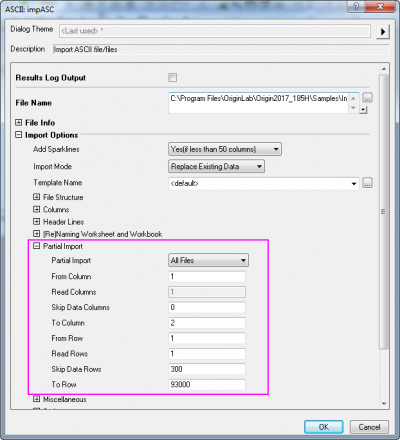
导入大型数据集
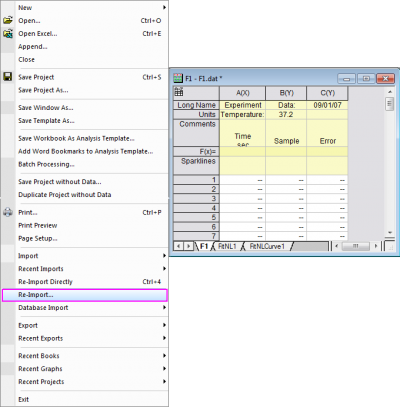
Origin 中的许多导入操作均支持部分导入,例如,允许导入 5 行,跳过下一个 20 行,再导入下一个 5 行……,按此方式直到数据导入完成。通过对大型数据集的部分导入,可以快速检查数据的性质,并可以在数据子集 (而不是整个数据集) 上进行各种绘图和分析操作。一旦对子集的绘图和分析结果满意,即可使用 Origin 重新导入功能来重新导入该数据集的全部内容。将分析结果和绘图都设为自动计算,则导入完整的数据之后这些结果和绘图都将自动更新。
分析大型数据集
除了具有部分导入的的功能之外,Origin 还具有灵活的工具可以以图形方式选择数据的范围。这些工具可以使您只在感兴趣的区域 (ROI) ,即已导入数据的子集上执行计算、数据处理、数据分析等操作。有以下几种选择数据的工具:
数据选择和数据标记
以图形方式选择开始和结束的数据范围,并将选出的数据用于分析。 ( Tools 工具栏上 ![]() 按钮)
按钮)
区域数据选择器 (Regional Data Selector)
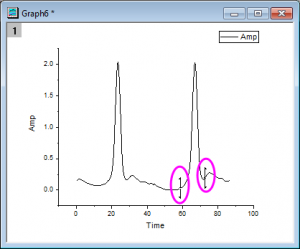
在一个或多个曲线上以图形方式定义一个或多个范围以进行分析。在 Tools 工具栏的区域数据选择器工具(Regional Data Selector)包括只选择活动曲线 ![]() 或区域内所有曲线
或区域内所有曲线
![]() 的选项。在进行选择时,可以选择使用矩形窗口或自由窗体形状。并将选出的数据用于分析。
的选项。在进行选择时,可以选择使用矩形窗口或自由窗体形状。并将选出的数据用于分析。
删减行或列
可以在执行分析或绘图之前删减数据。有关详细信息,请参阅 本博客 中的文章。
批处理多个数据文件
Origin 提供了一些批处理工具来批量分析或绘制多个数据文件。有关详细信息,请参阅 此博客文章 和 批处理教程 。
Keywords:large dataset, limitation, sampling interval, speed mode, skip rows, reduce, batch processing, regional selector, region, 大型数据集,限制,采样间隔,快速模式, 删减,跳行,批处理,区域选择, 部分数据