FAQ-987 Warum unterscheidet sich der Standardfehler des Mittelwerts aus der ANOVA von dem aus der Spaltenstatistik?
Letztes Update: 26.12.2018
Im Ergebnisblatt des Hilfsmittels ANOVA mit wiederholten Messungen in Origin gibt es eine Tabelle Deskriptive Statistik. Die Mittelwerte, Standardfehler des Mittelwerts in der Tabelle unterscheiden sich nicht unbeträchtlich von den Werten, die wir im Hilfsmittel Spaltenstatistik erhalten. Warum?
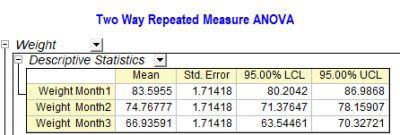
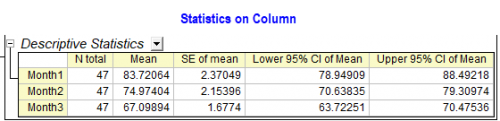
Dies liegt daran, weil es sich tatsächlich um zwei Arten von Mittelwert handelt, die nur einen sehr ähnlichen Namen im Bericht haben.
- Hilfsmittel ANOVA mit wiederholten Messungen
- Bei den Hilfsmitteln der ANOVA mit wiederholten Messungen ermitteln wir den Kleinste-Quadrate-Mittelwert (LS mean). Dies ist der Mittelwert für Gruppen, die für Mittelwerte von anderen Faktoren in einem linearen Modell wie eine ANOVA angepasst sind.
- Hilfsmittel Spaltenstatistik
- In der Spaltenstatistik ermitteln wir die beobachteten Mittelwerte. Das sind reguläre Mittelwerte, die direkt für Ihre Daten berechnet werden ohne Referenz auf ein statistisches Modell.
| Hinweise: Wenn Ihre Daten einem balancierten Design folgen, sind die Werte vom Kleinste-Quadrate-Mittelwert (LS Mean) und dem beobachteten Mittelwert gleich. In den beiden Hilfsmitteln sind nur Standardfehler, UKI und OKI unterschiedlich, basierend auf dem Algorithmus vom Kleinste-Quadrate-Mittelwert und beobachtetem Mittelwert. |