Algorithmus (Lineare Regression)
Inhalt
- 1 Das Modell der linearen Regression
- 2 Fit-Steuerung
- 3 Fit-Ergebnisse
- 4 ANOVA-Tabelle
- 5 Tabelle des Tests auf fehlende Anpassung
- 6 Kovarianz- und Korrelationsmatrix
- 7 Ausreißer
- 8 Residuenanalyse
- 9 Konfidenz- und Prognosebänder
- 10 Konfidenzellipsen
- 11 Y von X finden/X von Y finden
- 12 Residuendiagramme
Das Modell der linearen Regression
Einfaches lineares Regressionsmodell
Für einen gegebenen Datensatz \((x_i,y_i),i=1,2,\ldots n\) -- wobei X die unabhängige Variable und Y die abhängige Variable ist, \(\beta_0\) und \(\beta_1\) die Parameter sind, \(\varepsilon_i\) ein Zufallsfehlerterm mit Mittelwert \(E\left \{\varepsilon_i\right \}=0\) ist und die Varianz \(Var\left \{\varepsilon_i\right \}=\sigma^2\) -- passt die lineare Regression die Daten an ein Modell der folgenden Form an:
| \[y_i=\beta _0+\beta _1x_i+\varepsilon_i\] |
(1) |
|---|
Die Schätzung der kleinsten Quadrate wird verwendet, um die Summe von n quadrierten Abweichungen zu minimieren.
| \[\sum_{i=1}^{n}(Y_i-\beta_0-\beta_1X_i)^2\] |
(2) |
|---|
Die geschätzten Parameter des linearen Modells können folgendermaßen berechnet werden:
| \[\hat\beta _1=\frac{SXY}{SXX}\] |
(3) |
|---|
| \[\hat\beta _0=\bar y-\hat\beta _1\bar x \] |
(4) |
|---|
wobei:
| \(\bar x=\frac {1}{n}\sum_{i=1}^nx_i\),\(\bar y=\frac {1}{n}\sum_{i=1}^ny_i\) |
(5) |
|---|
und
| \(SXY=\sum_{i=1}^nx_iy_i\; \; \; \; \; \; \; SXX=\sum_{i=1}^nx_i^2\) (unkorrigiert) |
(6) |
|---|
| \(SXY=\sum_{i=1}^n(x_i-\bar x)(y_i-\bar y)\; \; \; \; \; \; \; SXX=\sum_{i=1}^n(x_i-\bar x)^2\) (korrigiert) |
(7) |
|---|
| Hinweis: Wenn der Schnittpunkt vom Modell ausgeschlossen ist, werden die Koeffizienten mit der unkorrigierten Formel berechnet. |
Daher schätzen wir die Regressionsfunktion folgendermaßen:
| \[\hat{y}=\hat{\beta_0}+\hat{\beta_1}x\] |
(8) |
|---|
Das Residuum \(res_i\) ist definiert als:
| \[res_i=y_i-\hat{y_i}\] |
(9) |
|---|
Die Formel in (2) muss so minimiert werden, dass sie gleich der Summe der Fehlerquadrate ist.
| \[RSS=\sum_{i=1}^nres_i^2\] |
(10) |
|---|
wenn die Schätzung der kleinsten Quadrate \(\hat{\beta_0}\) und \(\hat{\beta_1}\) zum Schätzen von \(\beta_0\) und \(\beta_1\) verwendet werden.
Fit-Steuerung
Fehler als Gewichtung
Im obigen Abschnitt wird angenommen, dass es eine konstante Varianz in den Fehlern gibt. Wenn wir jedoch die Versuchsdaten anpassen, müssen wir vielleicht den Fehler des Instruments im Anpassungsprozess berücksichtigen (der die Genauigkeit und Präzision eines Messinstruments wiedergibt). Daher wird die Annahme der konstanten Varianz in den Fehlern verletzt. Wir müssen annehmen, dass \(\varepsilon_i\) normalverteilt ist mit einer nicht konstanten Varianz und die Fehler als \(\sigma^2\) agieren, was als Gewichtung bei der Anpassung verwendet werden kann. Die Gewichtung wird definiert als:
| \[W=\begin{bmatrix} w_1& 0 & \dots &0 \\ 0 & w_2 & \dots &0 \\ \vdots& \vdots &\ \ddots &\vdots \\ 0& 0 &\dots & w_n \end{bmatrix}\] |
|---|
Das Anpassungsmodell wird wie folgt geändert:
| \[\sum_{i=1}^n w_i (y_i-\hat y_i)^2=\sum_{i=1}^n w_i [y_i-(\hat{\beta _0}+\hat{\beta _1}x_i)]^2\] |
(11) |
|---|
Die Gewichtungsfaktoren \(w_i\) können durch drei Formeln gegeben sein:
Keine Gewichtung
Der Fehlerbalken wird in der Berechnung nicht als Gewichtung behandelt.
Direkte Gewichtung
| \[w_i=\sigma_i \] |
(12) |
|---|
Instrumental
Der Wert der instrumentellen Gewichtung ist antiproportional zu Instrumentenfehlern, so dass ein Versuch mit kleinen Fehlern eine große Gewichtung haben wird, da er im Vergleich zu Versuchen mit größeren Fehlern präziser ist.
| \[w_i=\frac 1{\sigma_i^2}\] |
(13) |
|---|
| Hinweis: Die Fehler als Gewichtung sollten der Spalte "Y-Fehler" im Arbeitsblatt zugewiesen werden. |
Fester Schnittpunkt mit der Y-Achse (bei)
Fester Schnittpunkt mit der Y-Achse legt den Y-Schnittpunkt \(\beta_0\) auf einen festen Wert fest, während der Gesamtfreiheitsgrad n*=n-1 ist aufgrund des festgelegten Schnittpunkts mit der Y-Achse.
Skalierungsfehler mit Quadrat (Reduziertes Chi-Quadrat)
Die Option Skalierungsfehler mit Quadrat (Reduziertes Chi-Qdr.) ist verfügbar, wenn mit Gewichtung angepasst wird. Diese Option beeinflusst nur den Fehler auf die Parameter, die der Anpassungsprozess meldet, und nicht den Anpassungsprozess selbst oder die Daten in irgendeiner Weise. Die Option ist standardmäßig aktiviert, und \(\sigma^2\) wird zum Berechnen der Fehler auf die Parameter berücksichtigt. Ansonsten wird die Varianz von \(\sigma^2\) nicht zur Fehlerberechnung berücksichtigt. Nehmen Sie die Kovarianzmatrix als ein Beispiel: Skalierungsfehler mit Quadrat (Reduziertes Chi-Qdr.) verwenden:
| \[Cov(\beta _i,\beta _j)=\sigma^2 (X^{\prime }X)^{-1}\] | |
|---|---|
| \[\sigma^2=\frac{RSS}{n^{*}-1}\] |
(14) |
Keinen Skalierungsfehler mit Quadrat (Reduziertes Chi-Qdr.) verwenden:
| \[Cov(\beta _i,\beta _j)=(X'X)^{-1}\,\!\] |
(15) |
|---|
Für die gewichtete Anpassung wird \((X'WX)^{-1}\,\!\) anstatt \((X'X)^{-1}\,\!\) verwendet.
Fit-Ergebnisse
Wenn Sie eine lineare Anpassung durchführen, erstellen Sie ein Analyseberichtsblatt, dass die berechneten Eigenschaften enthält. Die Tabellenberichte Parameter modellieren Steigung und Schnittpunkt mit der Y-Achse (Zahlen in Klammern zeigen, wie die Eigenschaften abgeleitet werden):
Fit-Parameter

Angepasster Wert
Siehe Formel (3)&(4).
Die Parameterstandardfehler
Für jeden Parameter kann der Standardfehler, wie folgt, ermittelt werden:
| \[\varepsilon _{\hat \beta _0}=s_\varepsilon \sqrt{\frac{\sum x_i^2}{nSXX}}\] |
(16) |
|---|
| \[\varepsilon _{\hat \beta _1}=\frac{s_\varepsilon }{\sqrt{SXX}}\] |
(17) |
|---|
wobei die Beispielvarianz \(MSE\) (oder Quadrat des Mittelwertfehlers \(MSE\)) folgendermaßen geschätzt werden kann:
| \[s_\varepsilon ^2=\frac{RSS}{df_{Error}}=\frac{\sum_{i=1}^n (y_i-\hat y_i)^2}{n^{*}-1}\] |
(18) |
|---|
RSS steht für die Residuensumme des Quadrats (oder Fehlersumme des Quadrats, SSE), die tatsächlich die Summe der Quadrate der vertikalen Abweichungen von jedem Datenpunkt aus zur angepassten Linie darstellt. Es kann wie folgt berechnet werden:
| \[RSS=\sum_{i=1}^n e_i=\sum_{i=1}^n w_i (y_i-\hat y_i)^2=\sum_{i=1}^n w_i [y_i-(\beta _0+\beta _1x_i)]^2\] |
(19) |
|---|
| Hinweis: Im Bezug auf \(n*\), wenn der Schnittpunkt mit der Y-Achse in dem Modell enthalten ist, ist \(n*=n-1\). Ansonsten \(n*=n\). |
t-Wert und Konfidenzniveau
Gelten die Regressionsannahmen, haben wir:
| \(\frac{{\hat \beta _0}-\beta _0}{\varepsilon _{\hat \beta _0}}\sim t_{n^{*}-1}\) und \(\frac{{\hat \beta _1}-\beta _1}{\varepsilon _{\hat \beta _1}}\sim t_{n^{*}-1}\) |
(20) |
|---|
Die t-Tests können verwendet werden, um zu untersuchen, ob die Fit-Parameter signifikant von Null abweichen. Das bedeutet, wir können testen, ob \(\beta _0= 0\,\!\) (falls wahr, bedeutet dies, dass die angepasste Linie durch den Ursprung verläuft) oder \(\beta _1= 0\,\!\). Die Hypothesen der t-Tests sind:
- \(H_0: \beta _0= 0\,\! \) \(H_0: \beta _1= 0\,\!\)
- \(H_\alpha: \beta _0 \neq 0\,\!\) \(H_\alpha: \beta _1 \neq 0\,\!\)
Die t-Werte können wie folgt berechnet werden:
| \(t_{\hat \beta _0}=\frac{{\hat \beta _0}-0}{\varepsilon _{\hat \beta _0}}\) und \(t_{\hat \beta _1}=\frac{{\hat \beta _1}-0}{\varepsilon _{\hat \beta _1}}\) |
(21) |
|---|
Mit dem berechneten t-Wert können wir entscheiden, ob die entsprechende Nullhypothese verworfen werden soll oder nicht. Gewöhnlich können wir für ein gegebenes Konfidenzintervall \(\alpha\,\!\) die Hypothese \(H_0\,\!\) verwerfen, wenn \(|t|>t_{\frac \alpha 2}\). Außerdem wird der p-Wert oder die Signifikanzebene mit einem t-Test angezeigt. Wir weisen auch die Nullhypothese \(H_0\,\!\) zurück, wenn der p-Wert kleiner ist als \(\alpha\,\!\).
Wahrsch.>|t|
Die Wahrscheinlichkeit, dass \(H_0\,\!\) in dem t-Test oben wahr ist.
| \[prob=2(1-tcdf(|t|,df_{Error}))\,\!\] |
(22) |
|---|
wobei tcdf(t, df) die untere Wahrscheinlichkeit für die studentisierte t-Verteilung mit dem df-Freiheitsgrad berechnet.
UEG und OEG
Mit dem t-Wert können wir das \((1-\alpha )\times 100\%\)-Konfidenzintervall für jeden Parameter berechnen:
| \[\hat \beta _j-t_{(\frac \alpha 2,n^{*}-k)}\varepsilon _{\hat \beta _j}\leq \hat \beta _j\leq \hat \beta _j+t_{(\frac \alpha 2,n^{*}-k)}\varepsilon _{\hat \beta _j}\] |
(23) |
|---|
wobei \(OEG\) und \(LCL\) für Oberes Konfidenzintervall bzw. Unteres Konfidenzintervall steht.
KI halbe Breite
Das Konfidenzintervall halbe Breite ist:
| \[CI=\frac{UCL-LCL}2\] |
(24) |
|---|
wobei OEG und UEG das obere Konfidenzintervall bzw. untere Konfidenzintervall ist.
Statistik zum Fit
Die Schlüsselwerte der linearen Anpassung werden in der Statistiktabelle zusammengefasst (Zahlen in Klammern zeigen, wie Eigenschaften berechnet werden):
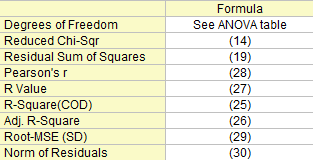
Freiheitsgrade
Der Freiheitsgrad des Fehlers Weitere Einzelheiten finden Sie in der ANOVA-Tabelle.
Summe der Fehlerquadrate
Die Residuensumme der Quadrate, siehe Formel (19).
Reduziertes Chi-Quadrat
Siehe Formel (14).
R-Quadrat (COD)
Die Qualität der linearen Regression kann mit dem Determinationskoeffizienten (COD) oder \[R^2\] gemessen werden, die folgendermaßen berechnet werden können:
| \[R^2=\frac{SXY}{SXX*TSS}=1-\frac{RSS}{TSS}\] |
(25) |
|---|---|
| \[TSS=\sum(y_i-\bar{y})^2\] |
wobei TSS die Gesamtsumme der Quadrate und RSS die Residuensumme des Quadrats ist. \(R^2\) ist ein Wert zwischen 0 und 1. Liegt er nahe 1, wird die Beziehung zwischen X und Y als stark betrachtet, und wir können einen höheren Konfidenzgrad in unserem Regressionsmodell haben.
Kor. R-Quadrat
Des Weiteren können wir den korrigierten \(R^2\) wie folgt berechnen:
| \[{\bar R}^2=1-\frac{RSS/df_{Error}}{TSS/df_{Total}}\] |
(26) |
|---|
R-Wert
Der R-Wert ist die Quadratwurzel von \[R^2\]:
| \[R=\sqrt{R^2}\] |
(27) |
|---|
Pearson r
Bei der einfachen linearen Regression ist der Korrelationskoeffizient zwischen x und y, der als r bezeichnet wird, gleich:
| \(r=R\,\!\) falls \(\beta _1\,\!\) positiv ist |
(28) |
|---|---|
| \(r=-R\,\!\) falls\(\beta _1\,\!\) negativ ist |
Wurzel-MSE (StAbw)
Quadratwurzel des Mittelwerts des Fehlers oder die residuale Standardabweichung ist gleich:
| \[RootMSE=\sqrt{\frac{RSS}{df_{Error}}}\] |
(29) |
|---|
Betrag der Residuen
Ist gleich der Quadratwurzel von RSS:
| \[Norm \,of \,Residuals=\sqrt{RSS}\] |
(30) |
|---|
ANOVA-Tabelle
Die ANOVA-Tabelle der linearen Anpassung ist:
| Freiheitsgrade | Summe der Quadrate | Mittelwert der Quadrate | F -Wert | Wahrsch. > F | |
|---|---|---|---|---|---|
| Modell | 1 | \[SS_{reg} = TSS - RSS\] | \[MS_{reg} = SS_{reg} / 1 \] | \[MS_{reg} / MSE \] | p-Wert |
| Fehler | n* - 1 | RSS | MSE = RSS / (n* - 1) | ||
| Gesamt | n* | TSS |
| Hinweis: Ist der Schnittpunkt im Modell enthalten, ist n*=n-1. Andernfalls ist n*=n und die Gesamtsumme der Quadrate ist unkorrigiert. Wenn die Steigung fest ist, ist \[df_{Model}\] = 0. |
Dabei ist hier die Gesamtsumme der Quadrate, TSS:
| \(TSS =\sum_{i=1}^nw_i(y_i -\frac{\sum_{i=1}^n w_i y_i} {\sum_{i=1}^n w_i})^2\) (korrigiert) | (31) |
|---|---|
| \(TSS=\sum_{i=1}^n w_iy_i^2\) (unkorrigiert) |
Der F-Wert ist ein Test, ob das Anpassungsmodell sich signifikant von dem Modell Y = konstant unterscheidet.
Der p-Wert bzw. die Signifikanzebene wird mit einem F-Test ermittelt. Wenn der p-Wert kleiner als \(\alpha\,\!\) ist, unterscheidet sich das Anpassungsmodell signifikant von dem Modell Y = konstant.
Wenn der Schnittpunkt mit der Y-Achse bei einem bestimmten Wert festgelegt wird, ist der p-Wert für den F-Test nicht bedeutungsvoll und unterscheidet sich von dem in der linearen Regression ohne die Nebenbedingung des Schnittpunkts mit der Y-Achse.
Tabelle des Tests auf fehlende Anpassung
Um den Test auf fehlende Anpassung auszuführen, müssen Sie sich wiederholende Beobachtungen zur Verfügung haben, d. h. "replizierte Daten" , so dass mindestens einer der X-Werte sich innerhalb des Datensatzes oder innerhalb mehrerer Datensätze wiederholt, wenn der Modus Zusammengefasster Fit ausgewählt ist.
Notationen, die für die Anpassung mit replizierten Daten verwenden werden:
| \(y_{ij}\) ist die j-te Messung, die beim i-ten X-Wert im Datensatz gemacht wurde. |
| \(\bar{y}_{i}\) ist der Durchschnitt von allen Y-Werten beim i-ten X-Wert. |
| \(\hat{y}_{ij}\) ist die prognostizierte Antwort für die j-te Messung, die beim i-ten X-Wert gemacht wurde. |
Die Summe der Quadrate in der Tabelle unten wird ausgedrückt mit:
| \[RSS=\sum_{i}\sum_{j}(y_{ij}-\hat{y}_{ij})^2\] |
|---|
| \[LFSS=\sum_{i}\sum_{j}(\bar{y}_{i}-\hat{y}_{ij})^2\] |
| \[PESS=\sum_{i}\sum_{j}(y_{ij}-\bar{y}_{i})^2\] |
Die Tabelle des Tests auf fehlende Anpassung der linearen Anpassung ist:
| Freiheitsgrade | Summe der Quadrate | Mittelwert der Quadrate | F -Wert | Wahrsch. > F | |
|---|---|---|---|---|---|
| Fehlende Anpassung | c-2 | LFSS | MSLF = LFSS / (c - 2) | MSLF / MSPE | p-Wert |
| Reiner Fehler | n - c | PESS | MSPE = PESS / (n - c) | ||
| Fehler | n*-1 | RSS |
|
Hinweis: Wenn der Schnittpunkt mit der Y-Achse im Modell enthalten ist, dann ist n*=n-1. Andernfalls ist n*=n und die Gesamtsumme der Quadrate ist unkorrigiert. Wenn die Steigung fest ist, ist \[df_{Model}\] = 0. c bezeichnet die Anzahl der eindeutigen X-Werte. Wenn der Schnittpunkt mit der Y-Achse festgelegt ist, ist der Freiheitsgrad für die fehlende Anpassung c-1. |
Kovarianz- und Korrelationsmatrix
Die Kovarianzmatrix der linearen Regression wird berechnet durch:
| \[\begin{pmatrix} Cov(\beta _0,\beta _0) & Cov(\beta _0,\beta _1)\\ Cov(\beta _1,\beta _0) & Cov(\beta _1,\beta _1) \end{pmatrix}=\sigma ^2\frac 1{SXX}\begin{pmatrix} \sum \frac{x_i^2}n & -\bar x \\-\bar x & 1 \end{pmatrix}\] |
(32) |
|---|
Die Korrelation zwischen zwei beliebigen Parametern ist:
| \[\rho (\beta _i,\beta _j)=\frac{Cov(\beta _i,\beta _j)}{\sqrt{Cov(\beta _i,\beta _i)}\sqrt{Cov(\beta _j,\beta _j)}} \] |
(33) |
|---|
Ausreißer
Die Ausreißer sind die Punkte, deren absolute Werte im studentisierten Residuendiagramm größer als 2 sind.
\[abs(Studentized Residual)>2\]
Studentisiertes Residuum wird in Ausreißer durch Transformieren der Residuen erkennen eingeführt.
Residuenanalyse
\(r_i\) steht für reguläres Residuum \(res_i\).
Standardisiert
| \[r_i^{\prime }=\frac{r_i}s_\varepsilon\] |
(34) |
|---|
Studentisiert
Sind auch bekannt als intern studentisierte Residuen.
| \[r_i^{\prime }=\frac{r_i}{s_\varepsilon\sqrt{1-h_i}}\] |
(35) |
|---|
Studentisiert gelöscht
Sind auch bekannt als extern studentisierte Residuen.
| \[r_i^{\prime }=\frac{r_i}{s_{\varepsilon-i}\sqrt{1-h_i}}\] |
(36) |
|---|
In den Gleichungen der studentisierten und studentisiert gelöschten Residuen ist \(h_i\) das i-te diagonale Element der Matrix \(P\):
| \[P=X(X'X)^{-1}X^{\prime }\] |
(37) |
|---|
\(s_{\varepsilon-i}\) bedeutet die Varianz wird berechnet, basierend auf alle Punkte, schließt aber den iten Punkt aus.
Konfidenz- und Prognosebänder
Für einen bestimmten Wert \(x_p\,\!\) liegt das \(100(1-\alpha )\% \)-Konfidenzintervall für den Mittelwert von \(y\,\!\) bei \(x=x_p\,\!\):
| \[\hat y\pm t_{(\frac \alpha 2,n^{*}-1)}s_\varepsilon \sqrt{\frac 1n+\frac{(x_p-\bar x)^2}{SXX}}\] |
(38) |
|---|
Und das \(100(1-\alpha )\% \)-Prognoseintervall für den Mittelwert von \(y\,\!\) bei \(x=x_p\,\!\) ist:
| \[\hat y\pm t_{(\frac \alpha 2,n^{*}-1)}s_\varepsilon \sqrt{1+\frac 1n+\frac{(x_p-\bar x)^2}{SXX}}\] |
(39) |
|---|
Konfidenzellipsen
Angenommen das Variablenpaar (X, Y) folgt einer zweidimensionalen Normalverteilung, so können wir die Korrelation zwischen zwei Variablen durch eine Konfidenzellipse untersuchen. Die Konfidenzellipse ist bei (\(\bar x\),\(\bar y\) ) zentriert und die große Halbachse a und die kleine Halbachse b können folgendermaßen ausgedrückt werden:
| \[ a=c\sqrt{\frac{\sigma _x^2+\sigma _y^2+\sqrt{(\sigma _x^2-\sigma _y^2)+4r^2\sigma _x^2\sigma _y^2}}2}\] | |
|---|---|
| \[ b=c\sqrt{\frac{\sigma _x^2+\sigma _y^2-\sqrt{(\sigma _x^2-\sigma _y^2)+4r^2\sigma _x^2\sigma _y^2}}2}\] |
(40) |
Für ein gegebenes Konfidenzniveau von \( (1-\alpha )\,\! \):
- Die Konfidenzellipse für die Grundgesamtheit Mittelwert wird definiert als:
| \[ c=\sqrt{\frac{2(n-1)}{n(n-2)}(\alpha ^{\frac 2{2-n}}-1)} \] |
(41) |
|---|
- Die Konfidenzellipse für Prognose wird definiert als:
| \[ c=\sqrt{\frac{2(n+1)(n-1)}{n(n-2)}(\alpha ^{\frac 2{2-n}}-1)} \] |
(42) |
|---|
- Der Neigungswinkel der Ellipse wird definiert als:
| \[\beta =\frac 12\arctan \frac{2r\sqrt{\sigma _x^2\sigma _y^2}}{\sigma _x^2-\sigma _y^2}\] |
(43) |
|---|
Y von X finden/X von Y finden
Residuendiagramme
Residuentyp
Wählen Sie einen Residuentyp unter Regulär, Standardisiert, Studentisiert, Studentisiert gelöscht für die Diagramme.
Residuen vs. Unabhängig
Punktdiagramm der Residuen \(res\) vs. unabhängige Variable \(x_1,x_2,\dots,x_k\); jede Zeichnung befindet sich in einem separaten Diagramm.
Residuen vs. prognostizierte Werte
Punktdiagramm der Residuen \(res\) vs. Anpassungsergebnisse \(\hat{y_i}\)
Residuen vs. die Ordnung der Datendiagramme
\(res_i\) vs. Abfolgenummer \(i\)
Histogramm des Residuums
Histogramm des Residuums
Verzögertes Residuendiagramm
Residuen \(res_i\) vs. verzögertes Residuum \(res_{(i–1)}\)
Wahrscheinlichkeitsnetz (Normal) für Residuen
Das Wahrscheinlichkeitsnetz der Residuen (Normal) kann verwendet werden, um zu prüfen, ob die Varianz ebenfalls normalverteilt ist. Wenn das sich ergebende Diagramm ungefähr linear ist, nehmen wir weiterhin an, dass die Fehlerterme normal verteilt sind. Das Diagramm basiert auf Perzentilen versus geordnete Residuen. Die Perzentile werden geschätzt mit
\[\frac{(i-\frac{3}{8})}{(n+\frac{1}{4})}\]
wobei n die Gesamtanzahl der Datensätze und i die i-ten Daten sind. Bitte lesen Sie auch Wahrscheinlichkeitsdiagramm und Q-Q-Diagramm.