誤差と重み付けを使ってフィットする
場合によっては、フィッティング計算に特定のデータポイントを他のものよりも重視したい場合があります。したがって、フィッティングのデータセットを選択するときは、設定タブのデータ選択ページの重み付け設定を行って、加重フィッティングを実行することもできます。
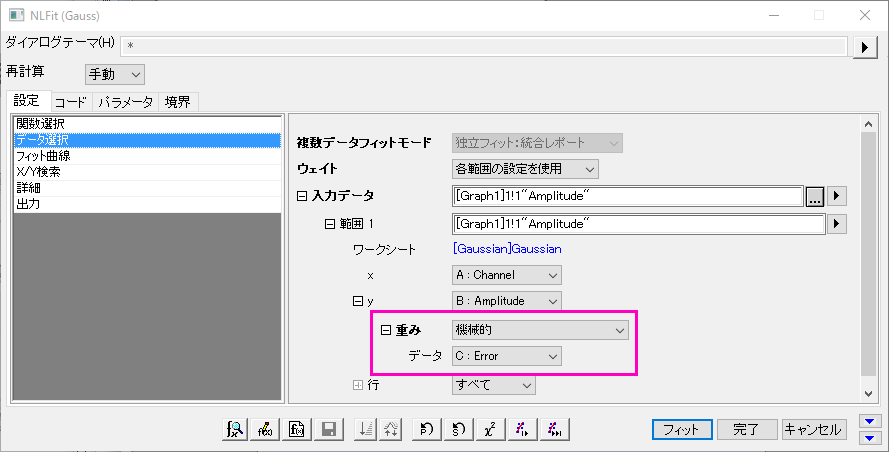
フィッティング後、次のような重み付けのある結果を得られます。
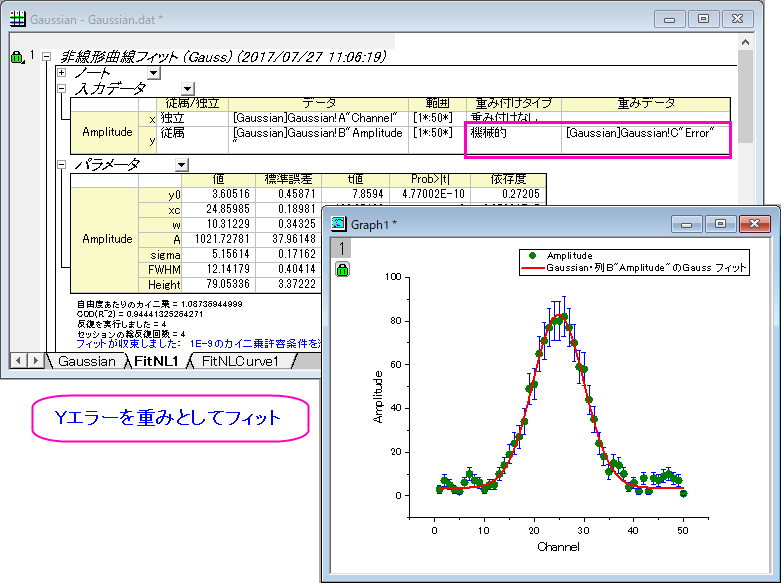
|
反復アルゴリズムが Levenberg Marquardtの場合、Yの重み付けのみ可能ですが、直交距離回帰(Orthogonal Distance Regression、Pro版のみ)の場合、XとYの重み付けがサポートされています。 |
複数の入力データセットがあるとき、各Y(またはX)データに異なる重み付け法を指定することが出来ます。重み付けは、カイ二乗が減少する手続きで使用されます。異なるケースで使用される式については、反復アルゴリズムを参照してください。
Originは、複数の重み付け法をサポートしており、いくつかはL-Mアルゴリズムでのみ使用できます。下表は各オプションで使用される式の一覧です。ここで、y は、関数パラメータ名を示し、従属変数を示すものではありません。
| L-M と ODR アルゴリズムで使用可能なオプション | 重み付け式 |
|---|---|
|
重み付けなし |
\[w_{i}=1\,\!\] |
|
機械的 |
\(w_{i}=\frac 1{\sigma _{i}^2}\,\!\)ここで\(\sigma _i\ \) は、エラーバー列に保存されるエラーバーの大きさです。 |
|
統計的重み付け |
\[w_{i}=\frac 1{y_{i}}\,\!\] |
|
任意データセット |
\(w_{i}=\frac 1{c_{i}^2}\,\!\) ここで \(c _{i}\,\!\) はその任意に指定されたデータセットの値 |
|
直接的重み付け |
\[w_{i}=c_{i}\,\!\] |
|
分散 ~ y^2 |
\[w_i=\frac 1{y_i^2}\,\!\] |
|
分散 = a*y^b |
\[w_i=\frac 1{ay_i^b}\,\!\] |
|
分散 = c^b+a*y^b |
\[w_i=\frac 1{c^b+ay^b}\,\!\] |
| L-M アルゴリズムのみで使用可能なオプション | 重み付け式 |
| 分散 = a*y^b*c^(tlast−t) |
\(w_i=\frac 1{ay_i^bc^{t_{last}-t_i}}\) ここで \(t_{last}\)、\(t _{i}\) はその任意に指定されたデータセットの値 |
|
分散 ~ yfit |
\[w_i=\frac 1{\hat y_i}\] |
|
分散 ~ yfit^2 |
\[w_i=\frac 1{\hat y_i^2}\] |
|
分散 = a*yfit^b |
\[w_i=\frac 1{a\hat y_i^b}\] |
|
分散 = c^b+a*yfit^b |
\[w_i=\frac 1{c^b+a\hat y_i^b}\] |
|
分散 = a*yfit^b*c^(tlast−t) |
\(w_i=\frac 1{a\hat y_i^bc^{t_{last}-t_i}}\) ここで \(t_{last}\)、\(t _{i}\) はその任意に指定されたデータセットの値 |